Le métier d’ingénieur en machine learning se situe à l’endroit où la data devient un produit fiable, mesurable et utile. On ne parle pas seulement d’entraîner des modèles: il faut choisir les bonnes données, tester, déployer, surveiller et travailler avec les équipes produit et tech. Dans cet article, je détaille le quotidien du métier, les compétences qui comptent vraiment, les formations qui ouvrent la porte en France et les repères de salaire les plus crédibles.
Les repères à avoir en tête avant de viser ce métier
- Le cœur du job est d’industrialiser des modèles d’IA, pas seulement de les prototyper.
- En France, le niveau attendu est le plus souvent un bac+5, avec une base solide en informatique, maths et statistiques.
- Les recruteurs regardent autant la qualité du code, la rigueur de test et la capacité de déploiement que la performance brute du modèle.
- Les rémunérations démarrent souvent autour de 40 à 55 k€ brut annuel, avec une montée rapide selon le secteur et l’expérience.
- Les profils qui progressent vite combinent Python, SQL, cloud, MLOps et sens produit.
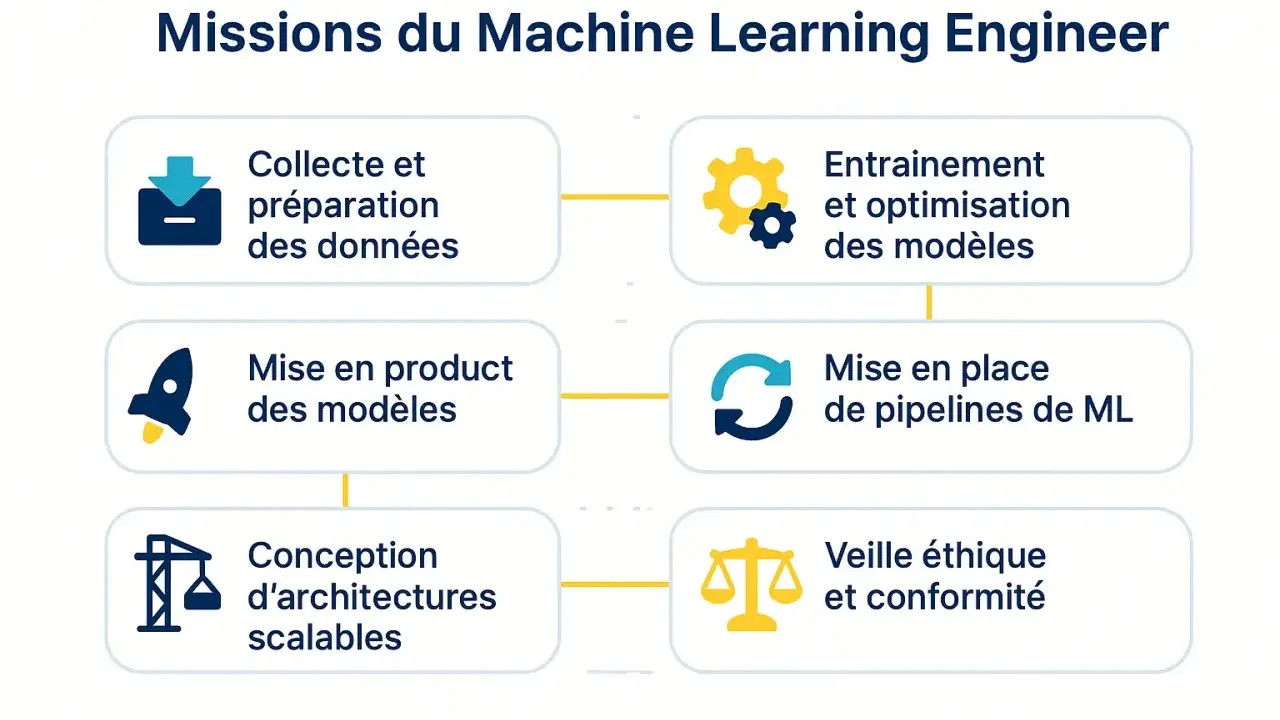
Ce que fait concrètement un ingénieur ML au quotidien
Je résume ce rôle en une formule simple: transformer un prototype de modèle en système fiable, mesurable et utile en production. Le quotidien va donc bien au-delà de l’entraînement: il faut cadrer le besoin métier, préparer des données propres, choisir une métrique pertinente, puis intégrer le modèle dans une application ou une API qui tiendra la charge. Dans les faits, c’est un métier de pont entre la data, le logiciel et le produit.
- Formuler le problème avec l’équipe métier ou produit: détection de fraude, recommandation, classification d’images, analyse de texte, prévision de demande.
- Préparer les données: nettoyage, sélection, annotation, contrôle de qualité et vérification des biais.
- Construire un premier baseline pour savoir si le sujet vaut vraiment l’investissement.
- Entraîner et comparer plusieurs modèles, puis expliquer pourquoi un choix est meilleur qu’un autre.
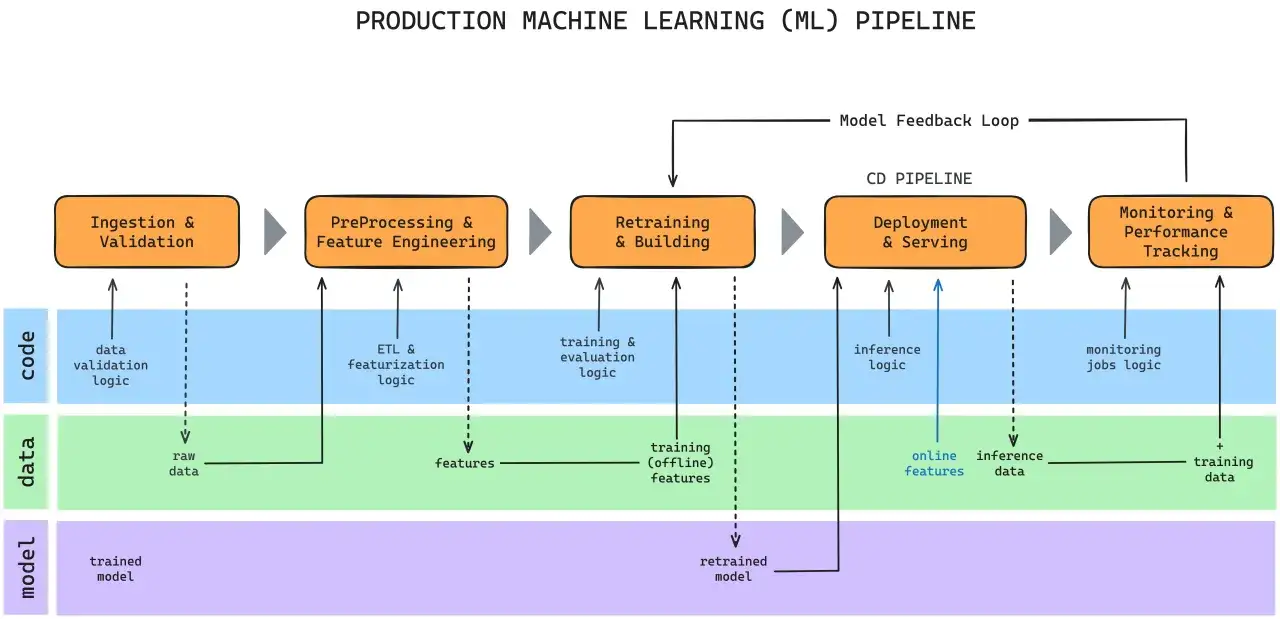
- Déployer en batch ou via API, avec des contraintes de latence, de coût et de sécurité.
- Surveiller le modèle après mise en ligne: dérive des données, baisse de performance, incidents de production.
Je trouve utile de voir ce métier comme un cycle complet, pas comme une étape unique. C’est justement ce passage du prototype au réel qui fait la valeur du poste, et qui explique pourquoi les compétences techniques seules ne suffisent pas.
Les compétences qui font vraiment la différence
Sur le terrain, je vois trois blocs de compétences qui comptent plus que les effets de mode. Il faut évidemment maîtriser l’algorithmique, mais aussi savoir faire parler les données, rendre le système maintenable et dialoguer avec des équipes qui n’ont pas toutes le même niveau technique.
| Compétence | Ce qu’on attend concrètement | Pourquoi c’est décisif |
|---|---|---|
| Python et écosystème data | Écrire du code lisible, tester ses fonctions, manipuler pandas, scikit-learn, PyTorch ou TensorFlow selon le contexte | Le modèle n’a de valeur que si le code est exploitable par d’autres et facile à maintenir |
| SQL et préparation des données | Extraire, joindre, filtrer et contrôler des jeux de données souvent imparfaits | La qualité des données pèse plus sur le résultat final que beaucoup de réglages d’algorithmes |
| Statistiques et évaluation | Choisir une métrique adaptée, lire une matrice de confusion, comprendre biais, variance et surapprentissage | Sans cela, on peut croire qu’un modèle marche alors qu’il échoue sur le terrain |
| MLOps et déploiement | Travailler avec Docker, CI/CD, MLflow ou des outils comparables, puis monitorer le modèle en production | C’est ce qui évite qu’un bon notebook reste un simple dossier local |
| Cloud et coût d’infrastructure | Comprendre le stockage, le calcul, les APIs et les compromis entre performance et budget | Un modèle trop coûteux ou trop lent perd vite son intérêt business |
| Communication et produit | Expliquer un choix technique, arbitrer entre précision, latence et simplicité, travailler avec le métier | Un bon profil ML sait défendre un compromis, pas seulement un score |
| Anglais technique | Lire la documentation, suivre les publications, comprendre les bibliothèques et les conventions du secteur | La littérature, les outils et une grande partie des bonnes pratiques passent par là |
Je me méfie toujours des profils qui ne parlent que de performance modèle. En production, une baisse de résultat peut venir d’un changement dans les données, d’un pipeline fragile, d’un mauvais seuil de décision ou d’une hypothèse métier mal posée. C’est là que la rigueur compte, et c’est aussi ce qui prépare la question suivante: comment entrer dans le métier sans se tromper de parcours.
Les parcours de formation qui ouvrent les portes en France
En France, le chemin le plus fréquent reste un bac+5. Les fiches métier publiques convergent vers cette logique: école d’ingénieurs, master en informatique, data ou intelligence artificielle, parfois avec une spécialisation plus poussée en mathématiques appliquées. Je privilégie toujours les profils qui ont accumulé des stages, de l’alternance ou des projets sérieux, parce qu’un diplôme rassure mais ne remplace pas les preuves de travail.| Parcours | Pour qui | Atout principal | Limite fréquente |
|---|---|---|---|
| École d’ingénieurs | Profil scientifique qui veut une base large | Solide culture maths, informatique et projet | Le ML peut rester trop théorique si les stages sont faibles |
| Master informatique, data ou IA | Étudiant qui veut une spécialisation plus directe | Accès clair aux sujets d’apprentissage automatique | Il faut compenser par des projets concrets et du code visible |
| Double compétence maths / informatique | Profil très analytique | Bonne base pour la modélisation et l’évaluation | Le risque est de sous-investir l’ingénierie logicielle |
| Doctorat | Profil orienté recherche ou problèmes avancés | Crédibilité forte sur des sujets complexes | Pas indispensable pour la plupart des postes produit |
| Reconversion structurée | Professionnel du développement ou de la data | Vitesse si la base logicielle existe déjà | Un bootcamp seul ne compense pas un manque de maths et de pratique |
Je conseille souvent de choisir le parcours le plus court qui permet d’obtenir trois preuves nettes: du code propre, un projet ML déployé et une vraie compréhension des données. Ensuite, le sujet devient beaucoup plus concret: combien vaut ce type de profil sur le marché français.
Combien cela paie et où les opportunités se trouvent
Les rémunérations varient fortement selon la ville, le secteur et surtout la capacité à livrer en production. Sur des annonces récentes vues chez Apec, les fourchettes tournent souvent autour de 40 à 55 k€ brut annuel pour des postes ML ou data, avec des niveaux à 55 à 70 k€ quand le poste devient plus spécialisé, plus senior ou plus exposé aux sujets LLM, vision ou MLOps. En début de carrière, cela place souvent le profil autour de 3 300 à 4 200 € brut par mois, avant bonus, intéressement ou variation géographique.
Les secteurs qui recrutent le plus ne sont pas toujours ceux qu’on imagine en premier. Je regarde surtout:
- La fintech et l’assurance pour la détection d’anomalies, le scoring et la lutte contre la fraude.
- L’e-commerce et le retail pour la recommandation, la prévision de demande et l’optimisation des stocks.
- L’industrie pour la maintenance prédictive, la vision et le contrôle qualité.
- La santé pour l’imagerie, l’aide au diagnostic et l’analyse de signaux.
- Les startups et scale-ups pour des postes plus transverses, souvent plus variés mais aussi plus exigeants en autonomie.
Ce qui compte le plus, à mon sens, ce n’est pas seulement le secteur: c’est la maturité data de l’entreprise. Un bon contexte vaut parfois mieux qu’un titre prestigieux, parce qu’il te donne plus vite l’occasion d’apprendre à livrer des systèmes réellement utiles.
Ne pas confondre avec les autres métiers data
Je vois souvent une confusion entre les rôles data, surtout chez les candidats qui préparent leur premier dossier. Or, les missions ne se recouvrent pas totalement, et c’est important de bien se positionner pour éviter un recrutement flou ou une candidature à côté de la plaque.
| Métier | Focus principal | Livrable attendu | Quand il est central |
|---|---|---|---|
| Data scientist | Explorer le problème, tester des hypothèses, produire des analyses et des prototypes | Études, modèles exploratoires, insights métier | Quand le sujet est encore peu défini |
| Data engineer | Construire et fiabiliser les flux de données | Pipelines, tables propres, architecture de données | Quand la base data est fragile ou incomplète |
| Machine learning engineer | Transformer un modèle en système exploitable | API, pipeline de scoring, déploiement, monitoring | Quand le cas d’usage est validé et doit passer à l’échelle |
| MLOps engineer | Automatiser, sécuriser et industrialiser le cycle de vie des modèles | CI/CD, orchestration, observabilité, retraining | Quand plusieurs modèles doivent être gouvernés proprement |
Dans une startup, un même poste peut cumuler deux ou trois de ces casquettes. Dans une grande entreprise, les rôles sont plus séparés. Cette distinction n’est pas théorique: elle aide à lire les offres, à préparer les entretiens et à comprendre ce que l’on vous demandera réellement dès les premières semaines.
Ce qui fait vraiment monter un profil machine learning en 2026
Si je devais donner un conseil unique à quelqu’un qui vise ce métier cette année, ce serait celui-ci: construis une preuve complète plutôt qu’un catalogue de notebooks. Un recruteur retient beaucoup plus facilement un projet qui a un vrai problème, une vraie donnée, un déploiement simple et une mesure d’impact qu’une série de scripts isolés.
- Un projet de bout en bout avec jeu de données, baseline, modèle final, API ou interface minimale.
- Des explications sur les choix: pourquoi ce modèle, pourquoi cette métrique, pourquoi ce seuil de décision.
- Une partie production avec versioning, tests simples, containerisation ou suivi d’expérience.
- Une attention au coût et à la latence, pas seulement à la précision.
- Un angle métier clair: fraude, recommandation, vision, texte, prévision, maintenance, selon la cible visée.
Les erreurs les plus fréquentes sont assez constantes: ne montrer que des notebooks, ignorer la dérive des données, oublier la qualité des features ou prétendre maîtriser trop de technologies à la fois. À mes yeux, le meilleur signal de maturité n’est pas la sophistication du modèle, mais la capacité à livrer quelque chose de robuste, lisible et rentable. Si tu vises ce métier, construis un portfolio qui montre un problème réel, des choix argumentés et un système qui continue de fonctionner après le premier déploiement: c’est là que le marché fait la différence.