Une formation data scientist sérieuse ne sert pas seulement à apprendre Python ou le machine learning ; elle doit vous amener à transformer des données brutes en décisions utiles pour une entreprise. En France, le sujet est particulièrement concret, parce que le marché valorise à la fois le niveau technique, la capacité à industrialiser un modèle et l’aptitude à parler avec les équipes métier. Dans cet article, je passe en revue les parcours de formation, les compétences à viser, les pièges à éviter et ce que le marché attend réellement en 2026.
L'essentiel pour choisir un parcours solide et viser un poste utile
- Le bac+5 reste la voie la plus sûre pour viser un poste de data scientist en France, surtout si vous partez de zéro.
- Les parcours courts fonctionnent surtout comme accélérateurs si vous avez déjà une base en maths, stats, informatique ou analyse de données.
- Python, SQL, statistiques, machine learning et data visualisation forment le socle minimal attendu au recrutement.
- Les projets concrets comptent autant que le diplôme : un portfolio bien construit rassure plus qu’un intitulé de cours flatteur.
- Le marché français reste porteur, mais les salaires et les attentes varient fortement selon le secteur, la région et l’expérience.
Ce que recouvre vraiment le métier de data scientist aujourd'hui
Je vois souvent une confusion simple : beaucoup de candidats imaginent encore le data scientist comme quelqu’un qui “fait de l’IA” en général. En réalité, le métier est plus large et plus exigeant. Il faut extraire, nettoyer, structurer, modéliser, tester puis expliquer les données, avec une vraie logique de bout en bout.
Dans la pratique, cela veut dire travailler sur des sources parfois sales ou incomplètes, définir des variables utiles, construire un modèle statistique, puis vérifier s’il tient la route une fois confronté au terrain. On parle aussi d’industrialisation quand le modèle doit vivre dans un produit, un outil interne ou un flux de décision automatisé. C’est souvent là que la valeur créée devient visible.
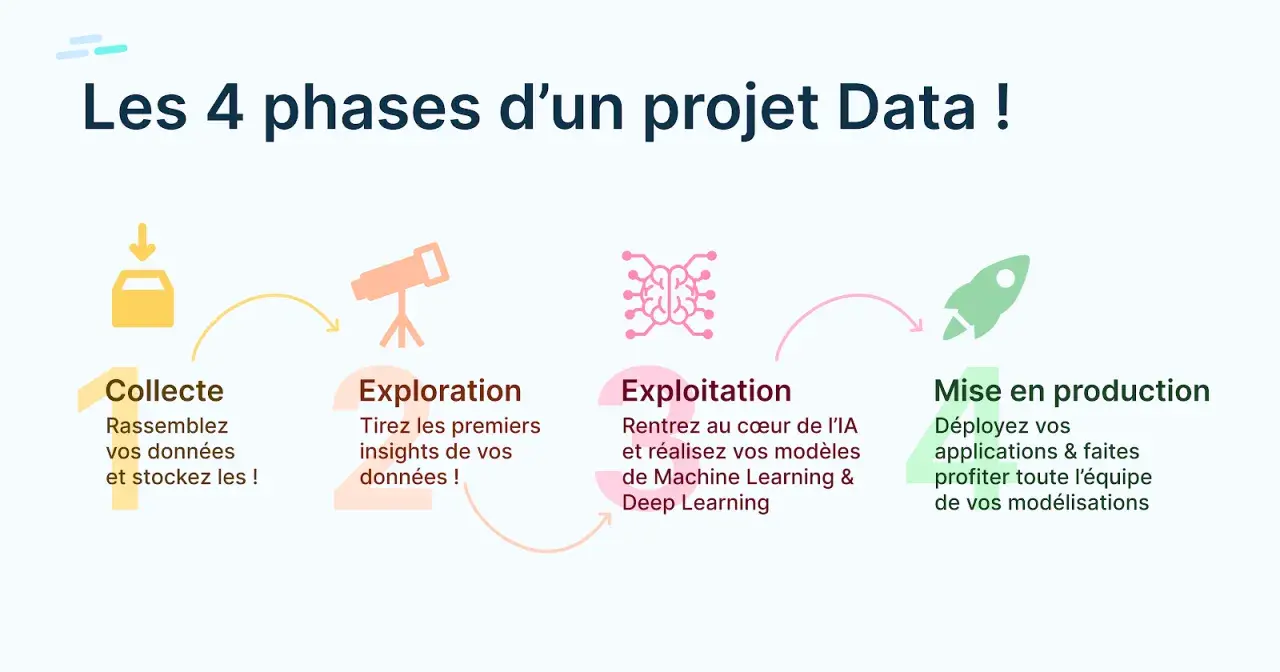
- Collecte et préparation : récupération via API, bases de données ou scraping, puis nettoyage des doublons et des anomalies.
- Modélisation : régression, classification, clustering, détection d’anomalies ou deep learning selon le besoin.
- Mise en production : intégration du modèle dans un système utilisable, avec supervision et maintenance.
- Traduction métier : explication des résultats à des équipes produit, marketing, finance ou direction.
Le métier change aussi selon le contexte. En banque, on peut travailler sur la fraude ; dans le commerce, sur la recommandation ou la segmentation client ; dans l’industrie, sur la maintenance prédictive ; dans la santé, sur l’aide au diagnostic ou l’exploitation de données complexes. C’est ce mélange de technique et de compréhension métier qui doit guider le choix du parcours.
Quel parcours de formation choisir selon votre point de départ
La bonne nouvelle, c’est qu’il n’existe pas un seul chemin. La moins bonne, c’est qu’un intitulé de formation peut être trompeur si le socle mathématique et technique n’est pas au rendez-vous. En France, la voie la plus reconnue reste le bac+5, mais il existe plusieurs formats selon votre profil de départ, votre niveau et votre temps disponible.
| Parcours | Durée typique | Pour qui | Atout principal | Limite à connaître |
|---|---|---|---|---|
| Master ou école d'ingénieurs | 5 ans d'études après le bac | Étudiants qui veulent un socle solide en maths, stats et informatique | Reconnaissance forte et base théorique robuste | Parcours long, sélectif, parfois moins flexible |
| MSc spécialisé | 1 à 2 ans après un bac+3 ou bac+4 | Profils déjà orientés data, informatique, maths ou économie | Bonne spécialisation et souvent davantage de projets appliqués | La qualité varie beaucoup selon l'école et les partenariats |
| Alternance | 1 à 2 ans | Ceux qui veulent apprendre en entreprise tout en se formant | Expérience concrète et employabilité plus rapide | Il faut trouver une entreprise adaptée, ce qui n’est pas automatique |
| Formation courte ou bootcamp | De quelques dizaines à quelques centaines d'heures | Reconversion ou montée en compétence sur un socle déjà existant | Rapide, concret, orienté pratique | Insuffisant seul si vous partez sans base en statistiques ou en programmation |
Le catalogue public des formations montre d’ailleurs des formats très contrastés, de 14 à 399 heures selon les programmes. Cela prouve une chose simple : tout ne se vaut pas, et une courte remise à niveau n’a pas le même objectif qu’un cursus complet. Si vous partez de zéro, je conseille de regarder en priorité les formations longues, l’alternance ou les parcours universitaires. Si vous avez déjà un bagage d’analyste, de développeur ou d’ingénieur, une montée en puissance plus courte peut être pertinente.
En pratique, un bon chemin de progression ressemble souvent à ceci : base en statistiques et en programmation, premier projet de data analysis, puis spécialisation en modélisation, puis confrontation à des cas réels en entreprise. Une fois ce cadre posé, la vraie question devient celle des compétences que le marché récompense vraiment.
Les compétences qui font réellement la différence au recrutement
Je préfère toujours raisonner en compétences utiles plutôt qu’en jargon de programme. Un recruteur ne cherche pas seulement quelqu’un qui “connaît l’IA” ; il veut une personne capable de produire un résultat fiable, compréhensible et exploitable. Voici le socle que je considère comme non négociable.
- Python : c’est la base la plus fréquente pour analyser, nettoyer et modéliser des données ; R reste utile dans certains contextes statistiques, mais Python domine largement les usages opérationnels.
- SQL : sans lui, impossible de travailler sérieusement avec les données d’entreprise ; savoir interroger et agréger des bases relationnelles reste un vrai marqueur de maturité.
- Statistiques : elles servent à comprendre la variance, le biais, les intervalles de confiance et la validité des résultats ; sans ce socle, on produit vite des modèles fragiles.
- Machine learning : il faut connaître les familles de modèles les plus courantes et savoir quand les utiliser ; la feature engineering, c’est-à-dire la création de variables plus pertinentes, fait souvent une grande partie du travail.
- Data visualisation : un bon graphique ou un tableau de bord clair vaut mieux qu’un long discours ; il sert à rendre une décision lisible.
- MLOps : ce terme désigne les pratiques qui permettent de déployer, surveiller et mettre à jour un modèle en production ; c’est souvent ce qui sépare un projet scolaire d’un vrai usage métier.
- RGPD et qualité des données : respecter la réglementation et travailler avec des données propres évite des erreurs coûteuses, techniques autant que juridiques.
- Communication : savoir expliquer une hypothèse, un résultat et ses limites est presque aussi important que le code lui-même.
Il faut aussi accepter une réalité : le niveau technique ne suffit pas. Les bons profils savent poser une question métier, choisir un bon indicateur, arbitrer entre précision et interprétabilité, puis défendre leur approche sans vendre du rêve. C’est précisément ce filtre qui permet d’éviter les formations séduisantes sur le papier mais pauvres en pratique.
Comment comparer une formation sans se laisser séduire par le marketing
Quand deux programmes se ressemblent sur la brochure, je regarde toujours la même chose : ce que l’étudiant produit à la fin. Un vrai cursus data doit laisser des traces tangibles, pas seulement une attestation. Si vous voulez évaluer un programme sérieusement, utilisez les critères ci-dessous.
| Critère | Ce qu'il faut vérifier | Pourquoi c'est important |
|---|---|---|
| Projets réels | Y a-t-il un cas complet, de la donnée brute au résultat exploitable ? | Le marché attend des preuves de capacité, pas seulement des cours suivis |
| Socle technique | Python, SQL, statistiques, visualisation, machine learning sont-ils tous présents ? | Un programme centré sur un seul outil crée vite des compétences bancales |
| Mise en production | Le programme parle-t-il d’API, de conteneurisation, de monitoring ou de déploiement ? | Un modèle non déployé reste un exercice de classe |
| Encadrement | Les retours sur travaux sont-ils réguliers et concrets ? | Les progrès en data viennent souvent de la correction fine, pas seulement de la théorie |
| Immersion entreprise | Stage, alternance, mission réelle ou projet sponsorisé par une société ? | La confrontation au terrain accélère l’autonomie et l’employabilité |
| Portfolio | Le programme aide-t-il à constituer un GitHub, un notebook propre ou une présentation métier ? | Au recrutement, un bon portfolio pèse souvent plus qu’un discours généraliste |
Les signaux d’alerte sont assez faciles à repérer : trop peu de code, aucune exigence en statistiques, pas de projet avec données imparfaites, pas de correction, et surtout aucune mention d’usage métier. Si une formation ne vous apprend pas à relier un problème business à une solution data, elle vous prépare mal au marché. Avec ces repères, on comprend mieux pourquoi deux formations portant le même nom peuvent conduire à des résultats très différents.
Ce que vaut le marché français en 2026
Le marché reste porteur, mais il faut lire les chiffres avec nuance. Selon l’Onisep, un débutant peut démarrer à partir de 2 660 € brut par mois, mais ce repère varie selon le lieu, le secteur et le niveau de spécialisation. L’Apec situe, dans ses offres, 80 % des rémunérations entre 35 k€ et 60 k€ brut annuel, pour une moyenne de 46 k€ ; c’est un repère crédible pour des postes cadres, pas une garantie automatique d’entrée.
Sur le portail public de l'emploi, la fourchette observée pour 80 % des offres tourne autour de 2 232 € à 3 941 € brut par mois, et certaines annonces récentes acceptent encore des débutants. En revanche, d’autres postes demandent déjà trois ans d’expérience, ce qui montre une réalité simple : la formation ouvre la porte, mais le portefeuille de projets et l’expérience terrain font souvent la différence.
Dans les grandes villes et les secteurs les plus matures, les attentes montent vite. Finance, conseil, e-commerce, santé, industrie et télécoms cherchent des profils capables de fiabiliser la donnée, de construire des modèles et de rendre les résultats utilisables. Dans une startup, le poste peut être plus large, avec de la segmentation client, des tests A/B, de la recommandation ou de l’optimisation de la conversion. Dans un grand groupe, la demande se déplace souvent vers la gouvernance, la robustesse et l’industrialisation. Le salaire ne suffit pourtant pas à juger un parcours, car les débouchés et la suite de carrière comptent tout autant.
Les débouchés qui s'ouvrent après une bonne base data
Le data scientist n’est pas une impasse, c’est souvent un point d’entrée vers des rôles plus spécialisés ou plus stratégiques. Le plus intéressant, à mes yeux, c’est que cette base donne une lecture très utile du produit, du client et de la performance. Dans l’univers des startups et du digital, cela devient vite un avantage décisif.
- Data analyst : bon chemin si vous aimez d’abord comprendre la performance, construire des tableaux de bord et raconter ce que disent les chiffres.
- Data engineer : pertinent si vous préférez les pipelines, la fiabilité des flux et l’infrastructure de données.
- Machine learning engineer ou MLOps : idéal si vous aimez le passage du prototype au produit, avec des contraintes de robustesse et de supervision.
- Lead data scientist ou head of data : évolution naturelle si vous prenez vite de la hauteur sur la stratégie, la priorisation et la coordination des usages data.
Dans une startup, un bon profil data apporte souvent plus qu’un modèle sophistiqué : il relie acquisition, rétention, pricing et produit. Dans un groupe plus structuré, il aide à cadrer les usages, à éviter les décisions intuitives mal fondées et à faire monter la culture data. Le vrai gain de carrière, au fond, vient quand on quitte le simple notebook pour devenir un interlocuteur capable d’influencer une décision.
Ce que je vérifie avant de m'engager dans un cursus data
Avant de signer, je vérifierais cinq choses très concrètes. D’abord, la formation me fait-elle travailler sur des données imparfaites et des problèmes métiers réels, ou seulement sur des exemples propres et artificiels ? Ensuite, ai-je du Python, du SQL, des statistiques, de la visualisation et un minimum de mise en production ? Sans cela, le programme restera trop théorique.
- Un projet de bout en bout : collecte, nettoyage, modélisation, restitution.
- Des retours réguliers : correction de code, d’analyses et de présentations.
- Un vrai portfolio : études de cas propres, lisibles et partageables.
- Une immersion : alternance, stage ou cas entreprise crédible.
- Un programme à jour : pas seulement des outils à la mode, mais aussi de la qualité des données, du RGPD et de l’industrialisation.
Si je devais résumer ma règle de choix, je prendrais une formation qui vous oblige à produire, expliquer et livrer, pas seulement à suivre des cours. C’est ce trio qui fait la différence sur le marché français, et c’est lui qui transforme une bonne base technique en vraie trajectoire de carrière.